Topics that don't need a category, or don't fit into any other existing category.
GIT show all branches creators
git for-each-ref --format='%(committerdate) %09 %(authorname) %09 %(refname)' --sort=committerdate
Export all Grafana data sources to data_sources folder
Export all Grafana data sources to data_sources folder
mkdir -p data_sources && curl -s "http://localhost:3000/api/datasources" -u admin:admin|jq -c -M '.[]'|split -l 1 - data_sources/
This exports each data source to a separate JSON file in the data_sources folder.
Load data sources back in from folder
This submits every file that exists in the data_sources folder to Grafana as a new data source definition.
for i in data_sources/*; do \
curl -X "POST" "http://localhost:3000/api/datasources" \
-H "Content-Type: application/json" \
--user admin:admin \
--data-binary @$i
done
Disable [Shift+Space] for change language in Ubuntu 20.04
xmodmap -e 'keycode 65 = space space space space'
Hyperledger Fabric - Anchor peer
Hyperledger Fabric - Anchor peer
Anchor peer это пир, который используется для обнаружения всех узлов, принадлежащих организациям в канале. Anchor peer должен быть доступен для всех пиров в канале.
У каждой организации в канале должен быть anchor peer (или несколько для предотвращения единой точки отказа), что позволяет пирам обнаруживать все существующие пиры в канале. Если в вашей организации нет anchor peer, ваши пиры смогут видеть только пиры своей организации. Если у организации нет anchor peer в канале, а к каналу присоединяется новый пир, организация не получит информацию об этом новом пире.
Например, предположим, что у нас есть три организации - orgA, orgB, orgC - в канале и один anchor peer в организации - peer0.orgC - определенный для организации C. Когда peer1.orgA из организации A связывается с peer0.orgC, он расскажет peer0.orgC о peer0.orgA. И когда позже peer1.orgB свяжется с peer0.orgC, peer0.orgC сообщит peer1.orgB о peer0.orgA. С этого момента организации orgA и orgB начнут напрямую обмениваться информацией без какой-либо помощи со стороны peer0.orgC.
Да в сети может быть один anchor peer, но рекомендуется использовать отдельные anchor peer для каждой организации.
Внешние и внутренние конечные точки
Для того чтобы сплетни работали эффективно, пиры должны иметь возможность получать информацию о конечных точках пирах в своей собственной организации, а также от пиров в других организациях.
Когда пир стартует, он использует peer.gossip.bootstrap в своем core.yaml для обмена информацией о членстве, делясь информацией обо всех доступных пирах в пределах своей собственной организации. Т.е использует peer.gossip.bootstrap для сплетен внутри своей организации.
Также можно использовать CORE_PEER_GOSSIP_ENDPOINT в docker-compose файле:
peer1:
- CORE_PEER_GOSSIP_BOOTSTRAP=peer2:7051
peer2:
- CORE_PEER_GOSSIP_BOOTSTRAP=peer1:7051
Для того, чтобы пиры в одной организации знали о существовании пиров в другой организации нужно использовать CORE_PEER_GOSSIP_EXTERNALENDPOINT:
peer1:
- CORE_PEER_GOSSIP_EXTERNALENDPOINT=peer1:7051
peer2:
- CORE_PEER_GOSSIP_EXTERNALENDPOINT=peer2:7051
GOLANG - go.sum (fix)
Delete conflict package sums:
sed '/^github.com\/hyperledger\/fabric v1.4.4/d' ./go.sum > temp.txt && mv temp.txt go.sum
DJANGO - ORM lookup classees
**Django 3.***
Доступные подклассы для выборки запросов типа:
"user_name__icontains"
"user_name__iregex"
"user_name__startswith"
django.db.models.query_utils :
'contained_by': <class 'django.contrib.postgres.fields.ranges.RangeContainedBy'>,
'gte': <class 'django.db.models.lookups.IntegerGreaterThanOrEqual'>,
'lt': <class 'django.db.models.lookups.IntegerLessThan'>,
'contains': <class 'django.db.models.lookups.Contains'>,
'endswith': <class 'django.db.models.lookups.EndsWith'>,
'exact': <class 'django.db.models.lookups.Exact'>,
'gt': <class 'django.db.models.lookups.GreaterThan'>,
'gte': <class 'django.db.models.lookups.GreaterThanOrEqual'>,
'icontains': <class 'django.db.models.lookups.IContains'>,
'iendswith': <class 'django.db.models.lookups.IEndsWith'>,
'iexact': <class 'django.db.models.lookups.IExact'>,
'in': <class 'django.db.models.lookups.In'>,
'iregex': <class 'django.db.models.lookups.IRegex'>,
'isnull': <class 'django.db.models.lookups.IsNull'>,
'istartswith': <class 'django.db.models.lookups.IStartsWith'>,
'lt': <class 'django.db.models.lookups.LessThan'>,
'lte': <class 'django.db.models.lookups.LessThanOrEqual'>,
'range': <class 'django.db.models.lookups.Range'>,
'regex': <class 'django.db.models.lookups.Regex'>,
'startswith': <class 'django.db.models.lookups.StartsWith'>,
SUBLIME - Anaconda plugin
SublimeText3 Anaconda (Python plugin)
https://sublime-text.zeef.com/zeefcom Anaconda config:
{ "pep8_ignore": [
"E501",
"E402",
"UnusedImport",
"W291",
"E722",
"E111"
] ,
"pyflakes_explicit_ignore": [
"UnusedImport",
],
"auto_formatting": true,
"autoformat_ignore":
[
"E309",
"E501",
],
"auto_complete": true,
"auto_complete_commit_on_tab": true,
}
Ubuntu Linux - 3+more monitors Artifacts fix
Ubuntu Monitor Artifacts FIX
1. Change GRUB config file:
gedit /etc/default/grub
Changed this line:
GRUB_CMDLINE_LINUX=""
to this:
GRUB_CMDLINE_LINUX="amd_iommu=on iommu=pt"
then:
sudo update-grub && sudo reboot
2. Update kernel iniframs:
git clone git://git.kernel.org/pub/scm/linux/kernel/git/firmware/linux-firmware.git
cd linux-firmware/
sudo cp -va amdgpu/ /lib/firmware/
sudo update-initramfs -u
reboot
SSH key to server
SSH => server
Create a key:
ssh-keygen -t rsa
Copy it to the server:
ssh-copy-id -i ./mainserver.pub archive@5.45.79.2
OR
ssh archive@5.45.79.2 "chmod 700 .ssh; chmod 640 .ssh/authorized_keys"
cat ./mainserver.pub | ssh archive@5.45.79.2 'cat >> .ssh/authorized_keys'
OR
ssh -i /root/.ssh/mainserver.pub archive@5.45.79.2
EXIFTOOL - Getting data from RAW (CR2) File to JPG (Ubuntu/Linux)
If you want to get data (in JPG) from your RAW file in Ubuntu/Linux, do next:
1) Install exiftool in your Linux system:
sudo apt install exiftool
2) not necessary step: view your RAW file data:
exiftool -s2 -all -b -X -fXMP:XMP foto.cr2
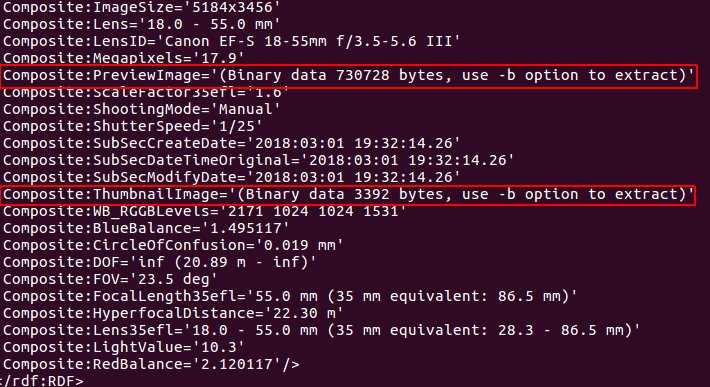
3) not necessary step: near the bottom, it will shows:
Composite:PreviewImage='(Binary data 1706501 bytes, use -b option to extract)'
Composite:ThumbnailImage='(Binary data 17031 bytes, use -b option to extract)'
4) Use the "-b" option to extract either or both:
exiftool -Composite:PreviewImage -b foto.cr2 >preview.jpg
exiftool -Composite:ThumbnailImage -b foto.cr2 >thumb.jpg
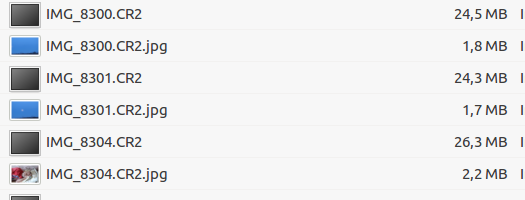
5) To extract data from all files in the folder, do next:
for i in *.CR2; do exiftool -Composite:PreviewImage -b $i > $i.jpg; done
6) Done. We did execute all JPG data from RAW files: